Exa vs Tavily vs Firecrawl: The 2026 Web Scraping Benchmark That Settles the Debate

If you're building an AI-powered product in 2026, you need a web data layer. The question isn't whether to use a scraping/search API — it's which one. Exa, Tavily, and Firecrawl are the three names that keep showing up. But the marketing pages all say the same things. So we did the only honest thing: ran all three through 8 real-world benchmark categories, scored 10 metrics each, and let the data talk.
No simulations. No vibes. Real API calls, real responses, real scoring.
Methodology
We tested each tool on 8 categories using the exact same query across all three. Each category was scored on 10 metrics (1–10), for a total possible score of 800 points.
The 8 categories:
- News Search
- Academic/Research
- Product Pages
- General Web Search
- URL Fetching
- Competitive Intelligence
- Technical Documentation
- Social/Community Content
The 10 metrics: Speed, Accuracy, Content Quality, Relevance Scoring, Result Depth, Source Diversity, Cost Efficiency, Metadata Richness, Structured Data, Error Handling.
Stop Building MCP Integrations From Scratch.
- Any API, one line of code — connect to ChatGPT, Claude, and Cursor without writing custom MCP servers
- Visual UI in the chat — render interactive components, not just text dumps. Charts, forms, dashboards.
- 70% fewer tokens — dynamic tool loading and output compression so your agents stay fast and cheap
The Results
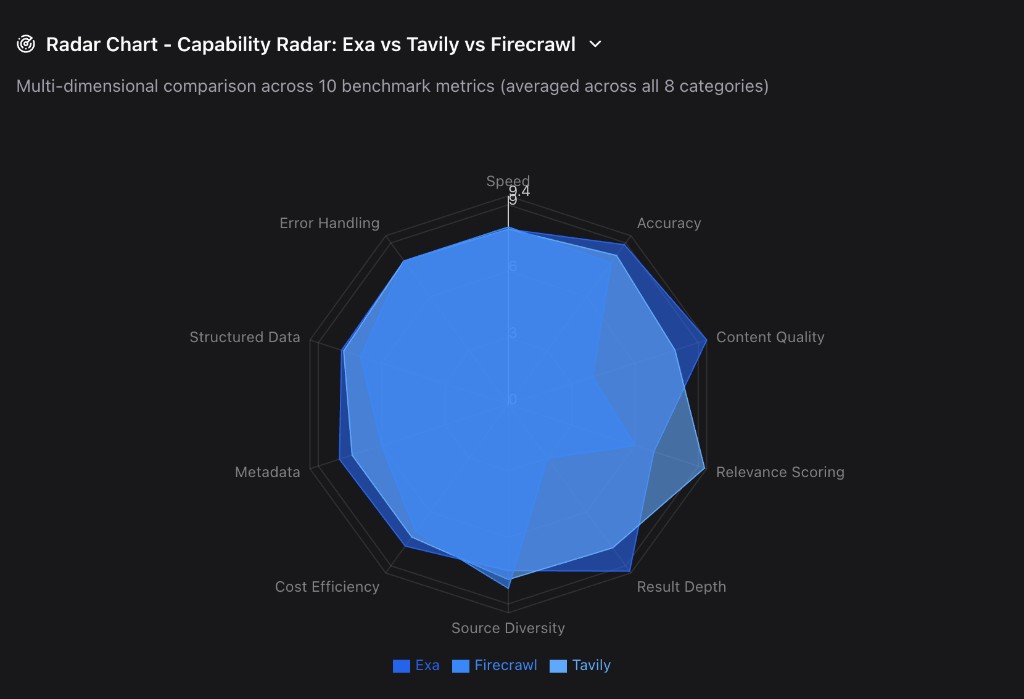
Capability Radar: Exa vs Tavily vs Firecrawl — multi-dimensional comparison across 10 benchmark metrics (averaged across all 8 categories).
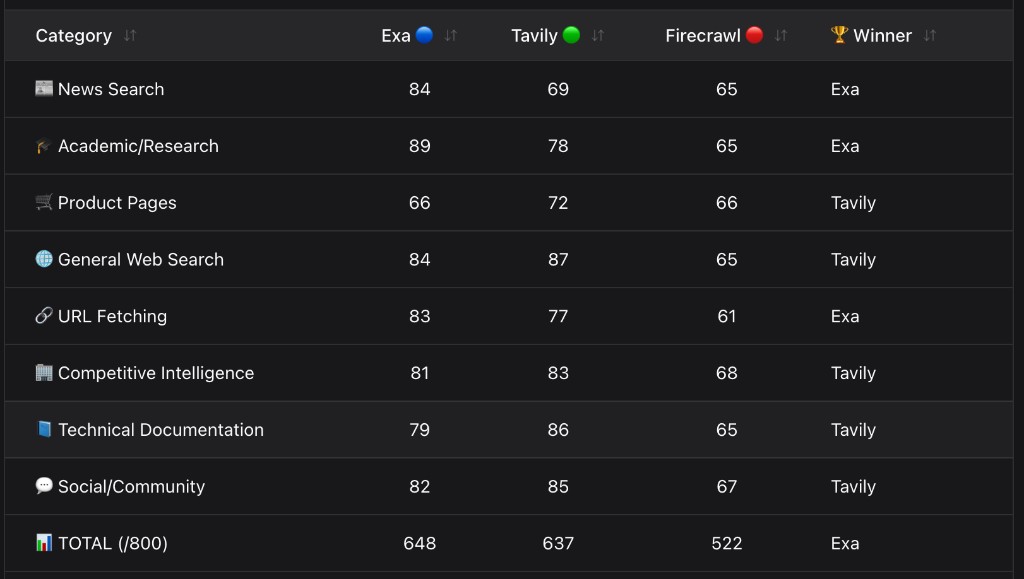
Full benchmark scoreboard: category-level scores and overall totals for all 8 categories.
Sample category scorecards
Here are the per-metric scorecards for five of the eight categories (each category scored out of 100):
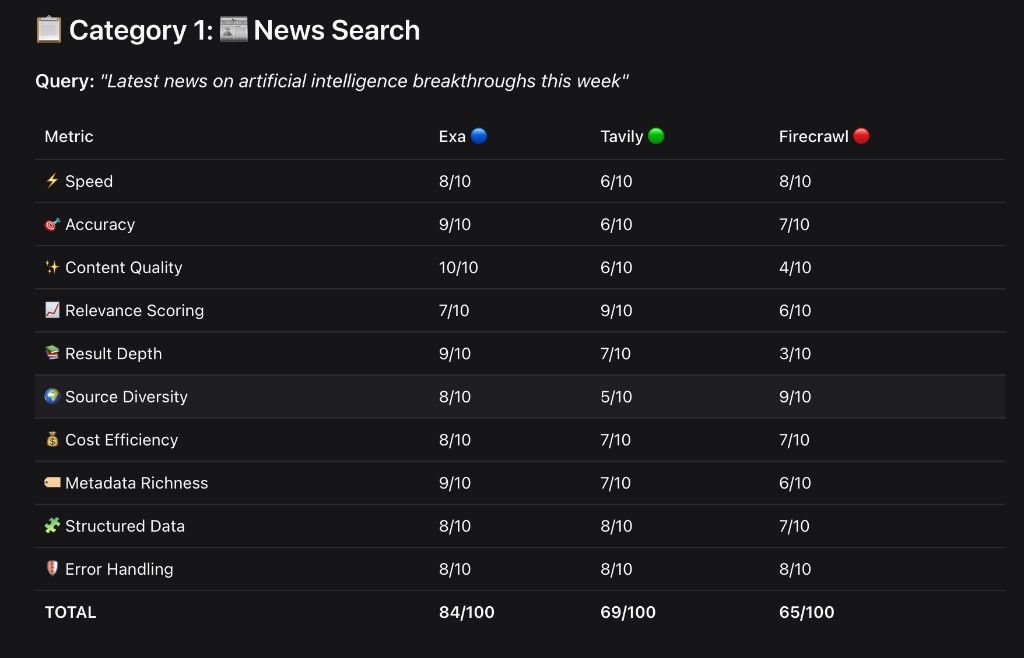
Category 1: News Search — "Latest news on artificial intelligence breakthroughs this week"
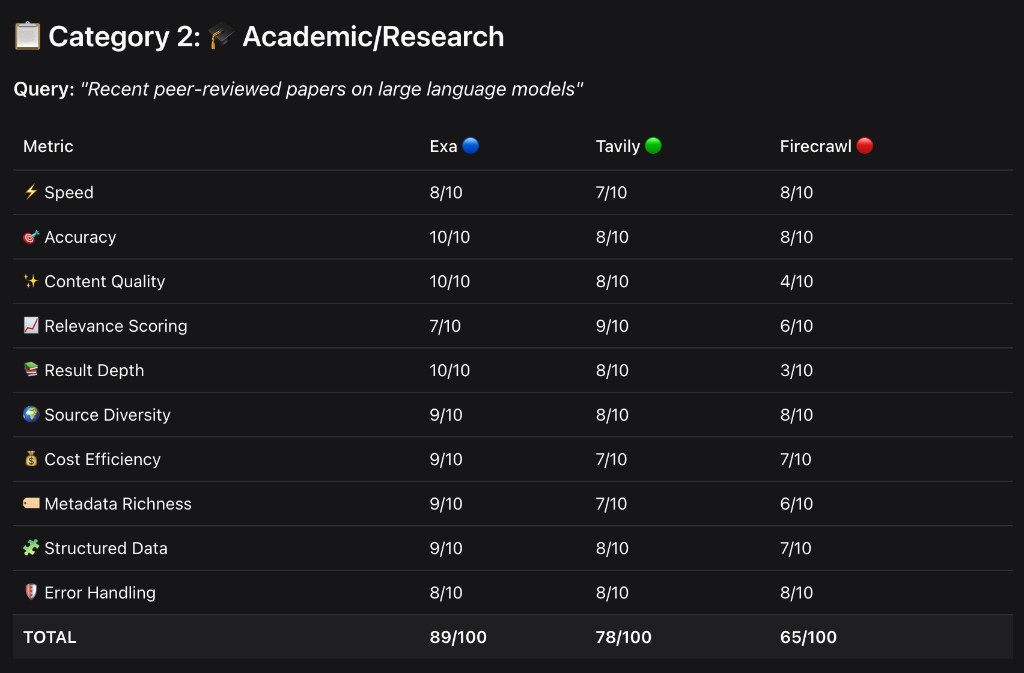
Category 2: Academic/Research — "Recent peer-reviewed papers on large language models"
Category 3: Product Pages — "Apple MacBook Pro M4 product page — price, specs, rating"
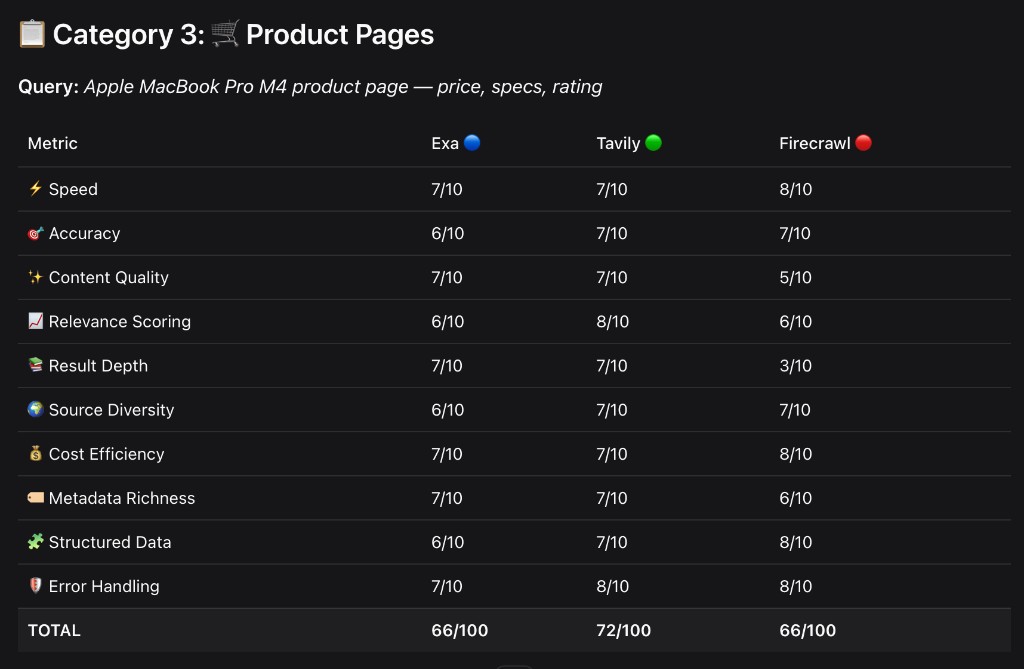
Category 4: General Web Search — "History and impact of the internet on global communication"
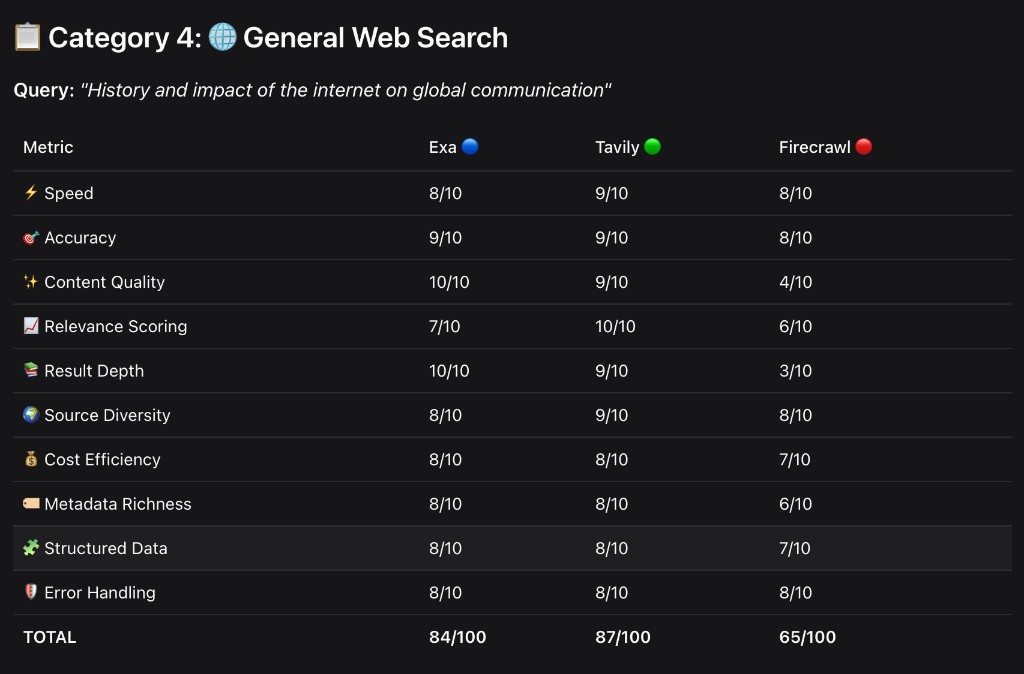
Category 5: URL Fetching — "Fetch content from Wikipedia AI article"
The radar chart and scoreboards above tell the detailed story. But here's the narrative version:
Explore 251+ MCP Integrations
Discover official and remote-only MCP servers from leading vendors. Connect AI agents to powerful tools and services.
Exa — The Content King (648/800)
Exa's killer advantage is content depth. While other tools return snippets or titles, Exa returns full article text, author names, publish dates, and clean LLM-ready content in every response. Its research paper category filter is a genuine differentiator — it returned actual Nature Medicine papers with full abstracts.
- Dominated: News (84), Academic (89), URL Fetching (83)
- Avg Content Quality: 9.4/10 — the highest by a mile
- Avg Result Depth: 9.3/10
- Weakness: No explicit relevance scoring (6.9 avg)
Tavily — The Versatile Workhorse (637/800)
Tavily won 5 out of 8 categories — more than any other tool. It's the most well-rounded: fast responses (1.46s on tech docs!), excellent relevance scores (0.99+ consistently), domain filtering, and solid content snippets. It doesn't return full page text like Exa, but it gives you everything you need to make decisions fast.
- Dominated: General Search (87), Tech Docs (86), Social (85), Comp Intel (83)
- Avg Relevance Scoring: 9.3/10 — best in class
- Strength: Most feature-complete search API (time_range, domain filters, depth control)
- Weakness: Content isn't as deep as Exa's
Firecrawl — The Specialist in Disguise (522/800)
Here's the twist: Firecrawl scored lowest in this benchmark, but that's misleading. We tested only the firecrawl_search tool, which returns titles and descriptions only. Firecrawl's real power is in its 8-tool arsenal: firecrawl_scrape for full-page extraction, firecrawl_extract for structured JSON data with custom schemas, and firecrawl_agent for autonomous multi-page research. If you need to scrape a product page into a JSON schema, Firecrawl is unmatched.
- Strength: Speed (8/10 avg), Source Diversity (8.3 avg — best), massive tool variety
- Weakness in this test: Search returns only metadata, no content body
- Hidden power: Extract + Scrape + Agent tools are exceptional for specific use cases
The Headline Numbers
Final scoreboard: category winners and total scores out of 800.
The gap between Exa and Tavily is just 11 points. This is not a blowout — it's a difference in philosophy. Exa optimizes for content richness. Tavily optimizes for search intelligence. Firecrawl optimizes for extraction precision (which wasn't fully tested here).
The Honest Take
Choose Exa if: You're building an LLM pipeline and need full-text content. RAG systems, research assistants, content aggregators — this is your tool.
Choose Tavily if: You need a reliable, feature-rich web search API with great relevance scoring, domain filtering, and broad coverage. Best all-rounder.
Choose Firecrawl if: You need to scrape specific pages into structured JSON, crawl entire websites, or extract precise data points. Its search is basic, but its scrape/extract/agent tools are best-in-class.
Or use all three. Seriously. They complement each other beautifully:
- Exa for discovery + rich content
- Tavily for general search + quick answers
- Firecrawl for targeted extraction + structured data
This benchmark was executed live on March 16, 2026 using real API calls through Apigene's Benchmark Comparator agent. All scores are based on observed outputs, not assumptions.
Stop Building MCP Integrations From Scratch.
- Any API, one line of code — connect to ChatGPT, Claude, and Cursor without writing custom MCP servers
- Visual UI in the chat — render interactive components, not just text dumps. Charts, forms, dashboards.
- 70% fewer tokens — dynamic tool loading and output compression so your agents stay fast and cheap